Causal Impact: Analyse der Auswirkungen von Ereignissen
Shapley-Werte zur Analyse der Feature-Relevanz
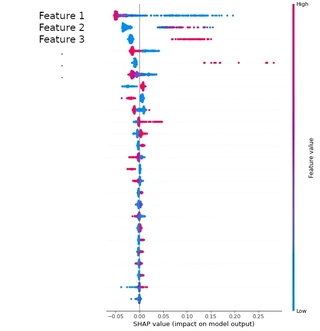
Bei jeder Aufgabe des Maschinellen Lernens geht es darum, Erkenntnisse aus Daten zu gewinnen. Das Modell erhält dazu Daten von angemessener Qualität als Eingabe. Es wird auf die aus den Eingabedaten abgeleiteten Features trainiert, um Vorhersagen in gewünschter Qualität zu erzeugen. Aber nicht alle Features sind für das Modell von derselben Relevanz. Einige sind sehr relevant, während andere nur Rauschen verursachen und die Rechenkomplexität erhöhen, ohne dass sie einen Nutzen bringen. Zudem ist es auch von geschäftlichem Wert, die wesentlichen Treiber für ein gegebenes Modell zu analysieren. Die Frage ist: Wie kann man dies technisch durchführen? Die einzigen ML-Modelle, die diese Auswertungsmöglichkeiten an Bord haben, basieren auf Entscheidungsbäumen, und selbst in diesen Fällen bleibt offen, ob eine Erhöhung des Feature-Werts zu einer Erhöhung oder einer Verringerung der Zielvariablen führt. Im Gegensatz dazu erlaubt das Konzept der Shapley-Werte nicht nur, dieses Manko zu beheben, sondern auch, die Feature-Relevanz allgemeiner Typen von Machine-Learning-Modellen jenseits von Entscheidungsbäumen zu bewerten. Bei diesem Ansatz wird jedes Feature systematisch nacheinander ausintegriert und durch geeignetes Hintergrundrauschen ersetzt, um seine Auswirkungen auf den Zielwert zu untersuchen. Die Analyse der Feature-Relevanz mit Hilfe von Shapley-Werten ist ein universelles Instrument , das wir in fast jedem Projekt in verschiedenen Branchen eingesetzt haben. Wir haben diese Methode im Einzelhandel eingesetzt, um die wichtigsten Faktoren für die Konversion zu ermitteln. Wir haben Shapley-Werte auch bei der Entwicklung eines Tools für Wissenschaftler eingesetzt, das Informationen darüber liefert, was an einem Experiment geändert werden sollte, um ein bestimmtes Ergebnis zu optimieren. Zum Einrichten des Algorithmus kann das Python-Paket SHAP verwendet werden. Dieses Paket befindet sich jedoch noch im Versuchsstadium, und Sie sollten darauf vorbereitet sein, dass von einer Version zur nächsten neue Bugs auftauchen könnten. Natürlich können Sie die Routine auch von Hand implementieren. Welchen Weg Sie auch immer wählen, bedenken Sie, dass die Erkenntnisse aus Ihrer Feature-Analyse in ihrer Zuverlässigkeit durch die Qualität des ML-Modells, auf das Sie sie anwenden, begrenzt sind. Wenn die Vorhersagequalität des Modells schlecht ist, wird auch die Feature-Analyse nicht viel wert sein.
Interpretation der Ergebnisse
Die nachstehende Abbildung zeigt eine beispielhafte Auswertung.